Adding Tables to your project
Tables come from dbt models that have been defined in your dbt project’sschema.yml files.
If your dbt model has been defined in a YAML file, and has at least one column documented, it will appear in Lightdash as a table.
For example, if we had this in our schema.yml files in dbt, we’d see a Table called Users in Lightdash.
Table configuration
You can customize how Tables look in Lightdash by adding configuration to your YAML file. Here’s an example of most the properties you can use when defining a Table:- dbt v1.9 and earlier
- dbt v1.10+ and Fusion
- Lightdash YAML
Table properties
Adding a new dbt model
If you’ve added a new dbt model to your project, you need to dodbt run + dbt refresh before it will appear in Lightdash.
Lightdash gets information about your data models from dbt. But it gets information about the data generated by those data models from your data warehouse.
This means that if you add a new dbt model to your project or update a model so that you’re making changes to the table it generates, then you need to do two things before your changes will appear in Lightdash:
- Materialize the new table or changes using dbt run. You want the data in your data warehouse to be the new table you’re expecting. So you need to do
dbt runto update the table from the data model you just changed. - Click Refresh dbt in Lightdash or run
lightdash refreshin the CLI. This will re-sync your dbt project in Lightdash so that changes you made to your dbt models are shown in Lightdash (e.g. adding a new table or column).
Order fields by
By default, the fields in your sidebar for any table will appear alphabetically (order_fields_by: "label"). Sometimes, you might not want your fields to appear alphabetically, but instead, in the same order as they are in your YAML file. You can achieve this by setting the order_fields_by parameter in your table’s meta tag to index, like this:
- dbt v1.9 and earlier
- dbt v1.10+ and Fusion
- Lightdash YAML
- user_id
- user_name
- user_email
order_fields_by parameter:
- By default,
order_fields_byis set tolabel, which means that your fields will appear in the table listed alphabetically. - Since metrics can be declared in multiple places within your YAML (as a dbt metric, in the model
metatag, under a dimension’smeta), we force the following order on metrics if you setorder_fields_bytoindex:- dbt metrics appear first
- then, metrics defined in the model’s
meta - then, metrics defined in the dimensions’
meta
- Group labels inherit the index of the first dimension that use them.
Groups
Usegroups to organize tables into nested groups in the sidebar. You can nest up to 5 levels deep by passing an array of group keys, ordered from outermost to innermost.
users table is placed under the mobile group, and within it, the engagement subgroup.
Group keys are referenced project-wide. Define their display labels and (optional) descriptions in your lightdash.config.yml file under table_groups:
table_groups, the key itself is used as the label.
The tables in your sidebar will appear in the following order:
- Grouped tables appear first, with groups sorted alphabetically by label
- Ungrouped tables appear after the grouped tables, alphabetically
- Tables within each group are also ordered alphabetically
The
groups property replaces the legacy group_label property. group_label still works for backwards compatibility but is deprecated — migrate to groups for nested group support.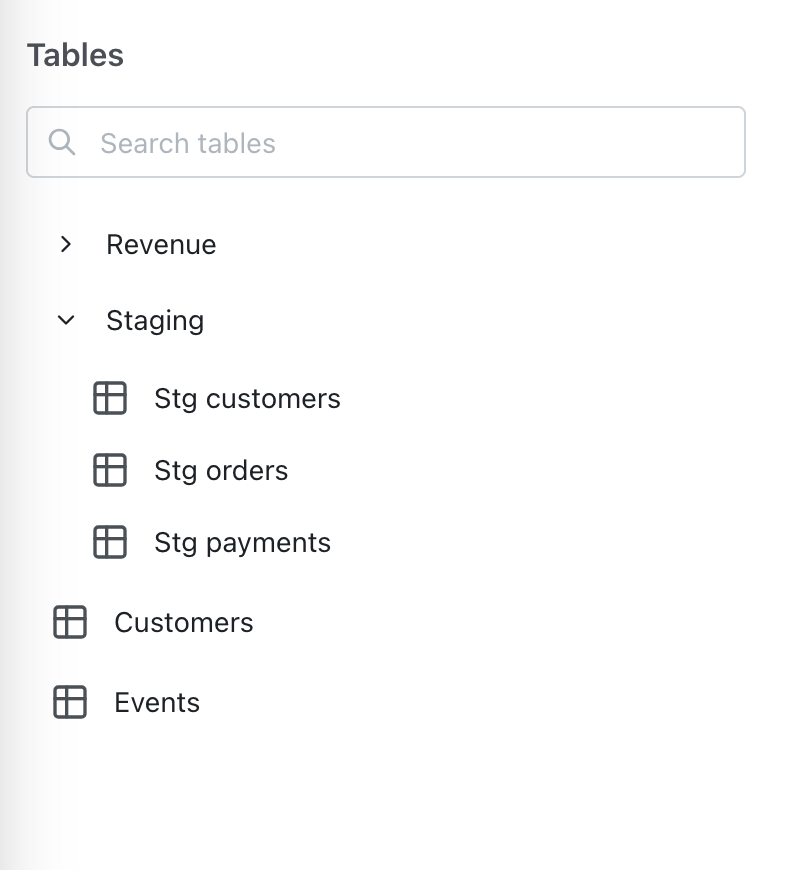
SQL from
sql_from is a configuration option that overrides the default dbt model relation name when generating SQL queries in Lightdash.
For example, you might use this if you want your Lightdash explore to query from a specific materialized view, a different schema, or include additional SQL logic in the FROM clause while still maintaining the dbt model structure for dimensions and metrics.
- dbt v1.9 and earlier
- dbt v1.10+ and Fusion
- Lightdash YAML
SQL filter (row-level security)
sql_filter adds a filter to the table that cannot be removed in Lightdash. It is automatically added to the compiled SQL when running queries.
For example:
- dbt v1.9 and earlier
- dbt v1.10+ and Fusion
- Lightdash YAML
Sales table in Lightdash will always have a filter for sales_region = 'EMEA' in their compiled SQL
Row-level security using user attributes
Usingsql_filter with user attributes allows you to set up row-level security in your tables. You can reference user attributes in your sql_filter using ${lightdash.attributes.my_attribute_name}
For example:
- dbt v1.9 and earlier
- dbt v1.10+ and Fusion
- Lightdash YAML
sql_filter will only be applied when querying tables directly.
For example:
- Table A is joined to Table B
- Table B has a
sql_filterapplied to it - A user queries Table A and adds a field from the joined table (Table B) to their query
- the
sql_filterfrom Table B will not be applied to the query (you would need to add this as asql_filterto Table A directly for it to apply)
If you reference a dimension from a joined table in your sql_filter, the referenced table will always be joined in your queries.
For example:
- You have Table A which is joined to Table B
- In Table A, you’ve added a
sql_filter: ${TABLE}.sales_region = 'EMEA' OR ${table_b}.sales_region IS NULL - Table B will always be joined to Table A in your queries (even if there are no fields from Table B selected in your results table)
Required attributes
Lightdash can use user attributes to limit some tables to some users. In the example below, only users withis_admin attribute true can use the payments table. Users without access to this table will not see it on the tables page or the explore page when joined to other tables.
- dbt v1.9 and earlier
- dbt v1.10+ and Fusion
- Lightdash YAML
Forbidden error.
Any attributes
Whilerequired_attributes uses AND logic (all conditions must match), any_attributes uses OR logic — a user only needs to match at least one condition.
- dbt v1.9 and earlier
- dbt v1.10+ and Fusion
- Lightdash YAML
required_attributes and any_attributes on the same table. When both are set, both checks must pass. See user attributes for details.
Defining primary keys
You can specify a primary key for your model to uniquely identify each row. This is important for tables as it helps Lightdash understand the relationships between tables and prevent data duplication, especially when dealing with SQL fanouts in joins. The primary key can be defined in two ways:Single column primary key
If your table has a single column that uniquely identifies each row, you can define it as a string:- dbt v1.9 and earlier
- dbt v1.10+ and Fusion
- Lightdash YAML
Complex primary key
If your table requires multiple columns to uniquely identify each row, you can define the primary key as an array of strings:- dbt v1.9 and earlier
- dbt v1.10+ and Fusion
- Lightdash YAML
Default show underlying values
You can set a defaultshow_underlying_values configuration at the model level that applies to all metrics in that model. This is useful when you want consistent underlying data visibility across all metrics without repeating the same configuration for each metric.
Individual metrics can override the model-level default by specifying their own show_underlying_values.
- dbt v1.9 and earlier
- dbt v1.10+ and Fusion
- Lightdash YAML
my_joined_table_name.my_dimension.
The order that the fields are listed in default_show_underlying_values is the order that they’ll appear in on the “View underlying data” table.
Default filters
Usedefault_filters to define filters on Dimensions that will be applied when no other user-defined filter on those Dimensions exists. Default filters will apply to tables on load and can be populated with a pre-determined value. Use them to suggest to users the kind of filters they might want to consider, or provide a default filtered view of a table that can be changed if needed.
An optional required flag can be added, and if this flag is set to required: true, the filter for this field cannot be removed from the UI but users can still modify the operator and value to adjust how this filter is applied to the data. This ensures the filter is always applied in some form, while giving users flexibility to change the date range or other values. This can be particularly useful if you have a large table and want to force users to filter on a partitioned date.
In contrast, when required: false (or omitted), the filter is pre-populated but fully editable — users can change the field, operator, value, or remove it entirely.
default_filters and required_filters can only target dimensions (including visible additional_dimensions). Hidden dimensions (hidden: true) are not valid targets and will fail compilation.
Below you can see there is a default filter with the optional required flag, that will have show the last 14 days of data by default.
- dbt v1.9 and earlier
- dbt v1.10+ and Fusion
- Lightdash YAML
Note: Required filters are not a security feature. For secure data access control, use user attributes.
If you have many filters in your list, they will be joined using AND
- dbt v1.9 and earlier
- dbt v1.10+ and Fusion
- Lightdash YAML
orders table will have a default filter of date in the past 14 days and status completed. Both can be removed by the user, as the required flag is not present.
Note that we do also support a legacy structure for defining required filters, see below:
- dbt v1.9 and earlier
- dbt v1.10+ and Fusion
- Lightdash YAML
Available filter types
Filter examples
Between operator (numeric):IN clause, e.g. WHERE status IN ('active', 'pending', 'approved').
milliseconds, seconds, minutes, hours, days, weeks, months, years
Complex example with multiple filters:
- dbt v1.9 and earlier
- dbt v1.10+ and Fusion
- Lightdash YAML
Filter notes
- Case insensitivity: Keywords like
between,AND,null,emptyare case-insensitive - Quotes: Use quotes for strings with spaces or special characters
- Escaping: Use
^to escape special characters (%,_,,,!,^) - AND logic: Multiple filters are automatically joined with AND
- Priority: Default filters only apply when no user-specified filter exists for that dimension
- Supported fields:
default_filtersandrequired_filtersapply to dimensions only (not metrics) - Hidden fields: Hidden dimensions (
hidden: true) cannot be used indefault_filters/required_filters
Case sensitive
You can control whether string filters are case sensitive or case insensitive at the table level. By default, all string filters are case sensitive (case_sensitive: true). When set to false, string filters on all dimensions in this table will ignore case differences when matching values.
This setting affects the following string filter operators: equals, not equals, starts with, ends with, includes, and doesn't include.
- dbt v1.9 and earlier
- dbt v1.10+ and Fusion
- Lightdash YAML
case_sensitive: false, filtering for “john” on any string dimension would match “John”, “JOHN”, “john”, etc.
Table-level
case_sensitive settings override the project-level default. Dimension-level settings override both. See Dimensions reference for dimension-level configuration and lightdash.config.yml reference for project-level defaults.Parameters configuration
Theparameters section allows you to define model-level parameters that can be referenced in various parts of your model’s SQL properties. These parameters are scoped to the specific model where they’re defined.
- dbt v1.9 and earlier
- dbt v1.10+ and Fusion
- Lightdash YAML
If using
options_from_dimension, the object requires the following properties:
Labeled options
Staticoptions can be authored as either plain values or { label, value } objects.
Using model-level parameters
Model-level parameters are referenced with the model name included in the syntax:${lightdash.parameters.model_name.parameter_name} or the shorter alias ${ld.parameters.model_name.parameter_name}.
For example, to reference a parameter named region from the current model:
Using parameters from joined tables
You can also reference model-level parameters from joined tables. This is particularly useful when you want to use parameters defined in one model while working in another:- dbt v1.9 and earlier
- dbt v1.10+ and Fusion
- Lightdash YAML
customer_status that is defined in the customers model, even though we’re configuring the orders model.
See the Parameters guide for more examples and information on how to use parameters.
Explores
You can define multiple table explores from a single table using theexplores config. This will allow you to list the same dbt model multiple times in the list of Tables in Lightdash. You can use it to show different versions of a table, join different tables to the base table, customize table visibility, etc.
Below is an advanced example of using Explores. This will result in three total tables using the deals model at the base.
- Deals will not have any joins or limitations
- Deals w/Accounts will join to the
accountstable and show all Accounts fields, but only people with theis_execuser attribute can see it - Deals w/Accounts (no Names) will join to the
accountstable and only show Industry and Segment dimensions, it has no access restrictions
- dbt v1.9 and earlier
- dbt v1.10+ and Fusion
- Lightdash YAML
explores tag.
Read this guide to learn more about explores
Sets
Sometimes you may find that you’re redeclaring the same set of fields for things like joins and show_underlying_values. In this case, you can define aset. A set allows you to associate those fields to a single value. That reference can then be used any place you would normally define fields.
Expand
The expand operator (ex.my_set*) tells Lightdash to look up the set being referenced and resolve it to the associated collection of fields. When Lightdash compiles your model, it will replace set reference names with the actual fields.
- dbt v1.9 and earlier
- dbt v1.10+ and Fusion
- Lightdash YAML
Exclusions
In the instance where you want to leverage some, but not all fields in aset, you can use the excludes operator (ex. -field_name). The exclusion needs to be used in conjunction with an expand operator. This tells Lightdash to expand a given set while omitting any field name using the exclusion operator.
- dbt v1.9 and earlier
- dbt v1.10+ and Fusion
- Lightdash YAML
Joins
Within a model, you may join with other model tables. The sets you define can reference those joined fields as well! Use dot notation to reference a joined table:- dbt v1.9 and earlier
- dbt v1.10+ and Fusion
- Lightdash YAML
set.